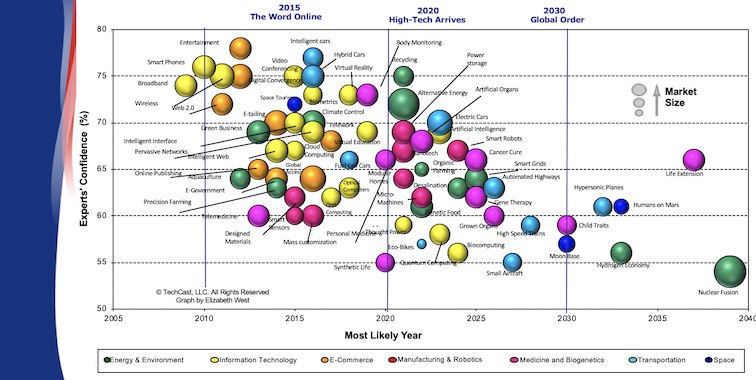
Halal and his team can provide high-quality strategic foresight services at competitive rates because we are a virtual organization drawing on the TechCast knowledge base, our more than 100 experts around the world, university colleagues and graduate students and the resources of Washington, DC. See Clients/Praise and Success Stories.
We have worked with AT&T, General Motors, SAIC, Blue Cross/Blue Shield, International Data Corporation, the US FDA, EPA, DoD, DNI and National Guard, NATO, Asian Development Bank, King Saud University in Saudi Arabia; MSIST in South Korea; Government of Singapore; MIMOS in Kuala Lampur; and other organizations.
Our associates specialize in solving problems related to strategic foresight:
- Strategic Research Studies on any technology, industry, organization or nation.
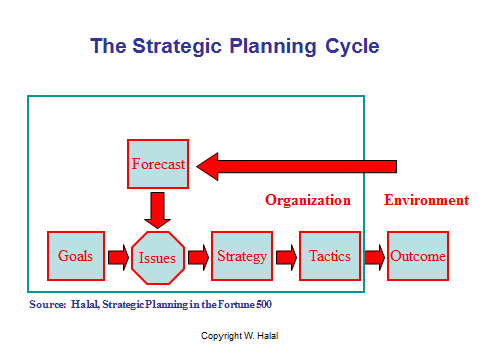
- Strategic Foresight and Planning Systems for organizations and units.
- Organizational Design and Change to create agile units integrating financial and social purpose.
- Training and Workshops on most aspects of strategic foresight.
- Speeches and Presentations on strategic topics to business and government.